8.2 Locking Mechanisms — Key Concepts Cheat Sheet
I've rambled on about a lot of prerequisites earlier, but to make sure we're on the same page, there are a few core principles about "locks" that bear repeating. Think of this as a cheat sheet — but remember, in concurrent programming, memorizing the rules and truly understanding them are two very different things. The latter requires paying some tuition in the form of debugging pain.
What is a Critical Section?
First, let's profile the enemy.
A critical section is a segment of a code path that can be executed concurrently by multiple execution paths (threads, processes, or even interrupt handlers), and this code reads or writes shared writable data.
As long as both conditions are met — concurrent execution + access to shared writable state — you have a critical section.
Sounds simple, right? But the devil is in the details.
What is a Critical Section Afraid Of?
Because it operates on shared writable data, a critical section is extremely fragile. It requires two different layers of protection:
-
Preventing Parallelism This means it must "stand alone." At any given time, only one execution flow can enter this code. This is what we commonly call mutual exclusion — forcibly turning parallel execution into serial execution.
-
Atomicity If you're running in an atomic context (such as an interrupt handler
ISR, a softirq, or holdingtasklet), you not only cannot be preempted, but you also cannot sleep. In this case, the critical section must execute indivisibly from start to finish. Any operation that requires waiting or sleeping is strictly contraband here.
Guarding the Critical Section: The Art of Locking
Since critical sections are so dangerous, how do we protect them? Step one is identification; step two is locking.
Identifying the critical section is the first and most crucial step. You must scrutinize your code like a bomb disposal expert: Who will access this global variable? Will that interrupt handler touch this linked list head? Miss one, and you've left a ticking time bomb.
Once identified, the usual protection mechanism is locking (of course, there's also the more advanced lock-free programming, but that's a high-level skill).
Here are two pitfalls that beginners fall into most often, and they deserve special attention:
❌ Bad Habit 1: Only Protecting Write Operations
"I'm only modifying the data, and you're all just reading, so it should be fine, right?"
Wrong. This is a very dangerous illusion. If you only protect writes and allow concurrent read and write operations to happen simultaneously, the read operation might fetch torn dirty data. Imagine the write operation is only halfway done (for example, it has written the first 32 bits of a 64-bit variable) when the read operation rushes in and grabs this incomplete value — this is what's known as torn read. What you read is neither the old value nor the new value, but a meaningless garbage value.
❌ Bad Habit 2: Using the Wrong Lock Object
"I used a lock, so why did it still blow up?"
Look back at your code. When protecting the same data structure, are you using the same lock variable?
This is another fatal error: using the wrong lock, or using different locks in different code paths to protect the same resource. It's like trying to use your front door key to open the back door lock — not only won't it open, but you might break the key off inside. Protection is only valid when all places accessing that data use the exact same lock.
When Protection Fails: Data Races
If you fail to protect it, or don't protect it at all, you end up with a data race.
Data races are the root of all evil in concurrent programming. In this scenario, the program's output no longer depends on code logic, but on — luck. This is known as timing dependency. This type of bug is a classic "Heisenbug": when you try to observe it with a debugger, it might disappear or change its behavior, because the act of observation itself alters the execution timing.
Once this kind of bug makes it into production, reproducing it, locating it, and fixing it will make you nostalgic for the days of writing business logic.
There's a deeper story behind data races, which we'll dive into in the next subsection.
When Can You Skip Locking?
To save you from developing paranoia, here are a few exceptional cases where you do not need to add locks.
-
Local Variables If you're working with local variables, they reside on the private stack of the process (or interrupt). Since they're private, there's no sharing, making them naturally safe.
-
Naturally Serialized Code Some code is logically guaranteed to run only once. For example, the
initandcleanupfunctions in our kernel module — they only execute once duringinsmodandrmmod, so there's absolutely no concurrency risk. -
Truly Read-Only Data If the data is a true constant (read-only), then everyone can read it however they please. However, be careful with C's
constkeyword — sometimes it only enforces read-only behavior at compile time and doesn't guarantee the data is truly unmodifiable at runtime. -
Explicitly Marked Plain Accesses There's also a special case explicitly documented in the kernel regarding when plain C language memory accesses are acceptable. The documentation is located at
tools/memory-model/Documentation/access-marking.txtin the source tree. Outside of that, exercise caution.
Understanding Data Races — Diving into LKMM
If you thought "one write, one read" was the full extent of data races, you might be underestimating the complexity of this issue.
As you dig deeper into concurrency topics, you'll discover a vast ocean of knowledge: memory ordering, memory barriers, lock-free programming, and more. Let's start with the most basic definition.
What Exactly is a Data Race?
The Linux kernel has its own memory consistency model called LKMM (Linux Kernel Memory Model). Under this model, the definition of a data race is extremely precise. It must simultaneously satisfy all four of the following conditions:
- Same Address: Both accesses target the same memory location.
- Concurrent Execution: The two accesses occur on different threads or different CPU cores (with no guaranteed ordering).
- At Least One Write: At least one of the two operations is a write.
- At Least One "Plain Access": This is the key! At least one of the two operations is a plain C-language access.
This last point is a blind spot that even many veterans overlook.
Look at the figure below (from Marco Elver's presentation at Linux Plumbers Conference 2020). It uses a table to intuitively show what constitutes a data race:
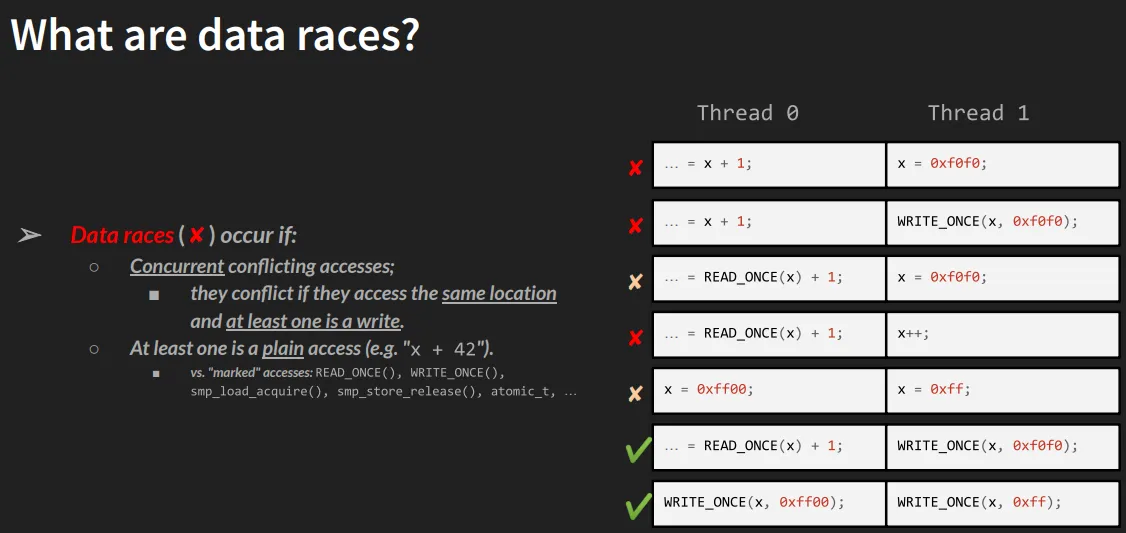
(Figure 8.2 – Screenshot from M Elver's presentation on data race detection in the kernel)
In the table, X represents a red alert (data race exists), and ✅ represents safe. Let's go through it row by row:
-
Row 1 (Race):
- Thread 0: Plain read (
READ(x)) - Thread 1: Plain write (
WRITE(x)) - Conclusion: A classic, textbook data race. One thread is reading while another is writing simultaneously, and both are plain C operations.
- Thread 0: Plain read (
-
Row 2 (Race):
- Thread 0: Marked read (Marked Read, such as
READ_ONCE(x)) - Thread 1: Plain write (Plain Write)
- Conclusion: Still a data race! Because "at least one is a plain access" and a write operation occurred. Even though Thread 0 conscientiously used a marked macro, Thread 1's barbaric operation ruined everything.
- Thread 0: Marked read (Marked Read, such as
-
Rows 3, 4, 5:
- Same principle as Row 2. As long as one side is "plain" and a write operation exists, a race is inevitable.
-
Rows 6, 7 (Safe):
- In these two rows, both Thread 0 and Thread 1 use marked accesses.
- For example,
READ_ONCE(),WRITE_ONCE(), or the more advancedatomic_t,refcount_t, and thesmp_load_acquire()family of macros. - These operations are designed to be atomic and follow LKMM's memory ordering rules.
- Conclusion: ✅ Safe.
What Does "Marked" Actually Mean Here?
Now we have to bring back that analogy — remember when we said plain C accesses are like "crossing the street without looking at the traffic lights"?
A "marked access" here is "looking at the traffic lights and using the crosswalk."
But the real world is harsher than analogies. Plain C statements (like int a = x;) can be freely optimized by the compiler — the compiler might cache them in a register, split them into two instructions, or reorder them with other instructions. This is fine in single-threaded code, but in a multi-core concurrent environment, it's a disaster.
The purpose of macros like READ_ONCE() / WRITE_ONCE() is to:
- Tell the compiler not to mess with it: Prevent the compiler from performing dangerous optimizations (such as merging multiple accesses or caching them in a register).
- Guarantee atomicity: Ensure aligned accesses complete within a single bus cycle.
- Make intent explicit: Tell anyone reading the code (and the KCSAN tool): "I've reached a concurrency boundary here, and I've handled it."
The Deep Waters of Knowledge
By this point, you should feel that the waters of concurrency run much deeper than you might have imagined.
To truly master it, you need to understand general concurrency concepts, memory ordering, memory barriers, LKMM, marked accesses, and the underlying mechanisms of lock-free programming... Each of these topics is worthy of its own book (in fact, the recommended reading LKP-2 has dedicated chapters covering these).
Since relying purely on the human brain to wrestle with such complex rules is already proving difficult, shouldn't we find some tools to help? Absolutely. In the next section, we'll bring in the "security scanner" of the kernel concurrency world — KCSAN.