正常
Deep Dive into C/C++ Compilation and Linking: Part 2 — Introduction to Static and Dynamic Libraries
What is Reuse, and How Does It Relate to Compilation and Linking?
Reuse is everywhere, and I'm sure no one would disagree. The reuse we discuss here is the reuse of code. In C++ programming, we can already see a glimpse of this:
Expand (22 lines)Collapse
cpp
template<typename AddType>
auto add(const AddType& a, const AddType& b){
return a + b; // 没有任何技巧的相加
}
std::string
trim_self(const std::string& waited_trim){ // returns the copy of the trimmed string
size_t i = 0; // left index
while (i < str.size() && isspace((unsigned char)str[i]))
i++;
size_t j = str.size(); // right index
while (j > 0 && isspace((unsigned char)str[j - 1]))
j--;
return str.substr(i, j);
}
int main()
{
int res = add(1, 2); // deduced as int
float res2 = add(1.0f, 2.0f); // deduced as floats
}For example, the template code and function code above mean we don't have to copy code repeatedly every time we perform addition or compress whitespace in strings. Looking at it this way, code reuse appeared way back in the era when C was dominant. However, I believe this level of code reuse isn't very advanced yet—because this reuse involves source code distribution. In other words, to use your own or someone else's code masterpiece, you have to frantically search for their source files, ensure all dependencies are present, and then add them to your project for compilation. I believe you noticed the problem—in many cases, we simply cannot obtain the source code (trade secrets, if you know, you know). In this situation, we naturally have to consider a lower level of code reuse. That is binary-level distribution. This is the role of static and dynamic libraries, and it is a prerequisite for the several reuse methods at the machine code distribution level that we will discuss later.
What is a Static Library?
Static libraries might be much simpler than you think. We know that after the compiler pre-processes and compiles source files, we obtain relocatable files. Previously, these relocatable files were directly combined into an executable file. Now, we can change our approach: these common relocatable files can be collected into a library. The next time we look for symbols, we simply link to this library. This way, we hide the source code and can distribute it at the binary level. However, there is a problem—how do we use it? We always need available symbols to tell us the exact entry point. Just like knowing a library has a function that compresses string whitespace, but if we don't know what it's called, we can't use it. So, it's obvious. Possessing these binary files alone is completely insufficient; we need to meet other conditions—that is—exported header files for our programming use.
The two figures below illustrate the role of static libraries well.
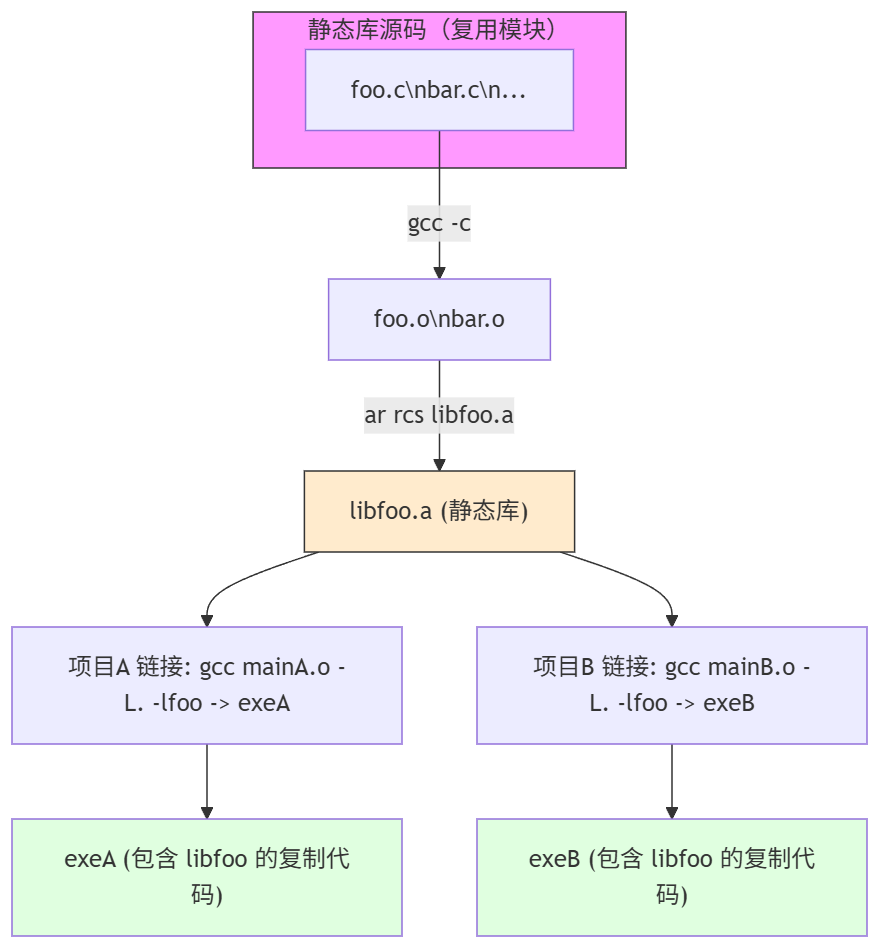
But this introduces a new problem. In reality, the code for libfoo is identical, yet there are two copies. We don't always want this kind of hard copying. If libfoo is small, it's fine; hard drive capacity is relatively inexpensive these days, so we can say redundancy has its advantages. However, in more cases, if libfoo has an important security update and we want all software to reload it on the next startup, static libraries seem powerless. Because they simply shifted distribution from the more difficult source code distribution to binary distribution, without solving the more important issue of "load when use." So it doesn't seem elegant. Therefore, in reality, static libraries are not used very widely (I personally rarely use static libraries).
Dynamic Libraries
So the problem lies in the fact that we performed a deep copy of all binary code, rather than a shallow copy at the reference level. If we allow a portion of the symbols in the executable code to be lazily loaded and determined (this requires us to have a loader that can dynamically load and modify the addresses of these undefined symbols to the real shared symbol addresses), we naturally think—we've reached the library level, so let's go a step further and simply turn this code into purely shareable code. When they need to be available, we load them, and subsequently all executable programs needing this library can safely and directly use this shared code segment without having to clumsily copy a copy themselves. This greatly saves our memory space. This sharing characteristic also allows us to say that a dynamic library is also a shared library (shared code inevitably requires dynamic loading to re-modify shared symbol addresses, so in this context, shared libraries and dynamic libraries are completely interchangeable, and no one deliberately distinguishes them today).
Of course, deeper characteristics of dynamic libraries—for example, to ensure that any executable program needing this library can successfully load symbols inside, we compile all symbols using the -fPIC method (Position Independent Code). This makes it very convenient for the loader to perform relocation.
Overview: How Do Dynamic Libraries Actually Work?
Building a Dynamic Library (From Source Code to libfoo.so / Versioned libfoo.so.1.0)
Goal: Generate a .so that can be dynamically loaded by clients and shared by multiple processes, ensuring clear ABI management (via SONAME/versioning).
This is factually almost identical to building an executable, except no startup headers are added. Beyond that, we need to ensure a few basic key points:
- Must use Position Independent Code (PIC):
-fPIC(or-fpic) is used to generate code that can run at any address (function memory access uses relative addresses or via GOT). Not using PIC will cause the linker/runtime to generate relocation conflicts or non-relocatable segments. - Use
-sharedto generate a shared object: The linker marks the type as a dynamic library (ELF type = DYN). - Set SONAME: Specify the ABI name via the linker option
-Wl,-soname,libfoo.so.1(the client records the SONAME in DT_NEEDED). The actual file is usuallylibfoo.so.1.0, providing symlinkslibfoo.so.1 -> libfoo.so.1.0andlibfoo.so -> libfoo.so.1(convenient for-lfooduring development). - Control exported symbols (visibility / version script): By default, global symbols are exported. You can use GCC
-fvisibility=hidden+__attribute__((visibility("default")))to mark interfaces needing export, or use a linker version script to control the symbol table, reducing API pollution and lowering symbol conflict risks. - Optional: Symbol versioning: Used to support different versions of symbols within the same SONAME, facilitating compatibility management (requires a linker version script).
Building the Client Executable (Based on "Trusting Library ABI/SONAME")
Here, "trusting" means the client trusts the dynamic library's ABI/interface (header files, SONAME, symbol semantics) during construction to not break its expectations. The relationship between the build phase and runtime, and the generated ELF fields, is critical.
What Happens at Link Time (Building the Client)
- The client uses header file declarations (
foo.h) and-lfooto link against the corresponding shared library (or the library's development symlinklibfoo.so). - The linker will:
- Merge the client's own code and object files into an executable file (ELF type = EXEC or DYN (Position Independent Executable)).
- Verify: Attempt to resolve undefined references (in the case of dynamic linking, the linker usually utilizes the dynamic symbol tables of the specified shared libraries to satisfy these references; if not found, it reports an undefined reference error).
- Do not copy library code: Unlike static linking, the linker does not copy
.ocode into the executable; instead, it records dependencies inDT_NEEDED(recording the library's SONAME) and generates necessary relocations/PLT placeholders.
- Result: The executable contains dynamic segment entries like
DT_NEEDED: libfoo.so.1, but does not contain the library's implementation code.
Runtime Loading and Symbol Resolution (Specific Behavior of the Dynamic Linker / Loader)
This is the most complex and critical part — at runtime, the ld.so (or the corresponding platform's loader) assembles everything into a runnable process address space and resolves symbol references. The details are explained step-by-step below.
Startup Phase — From Kernel to Dynamic Linker
- Kernel loads the executable: The kernel reads the ELF header -> If the
INTERPsegment exists in the ELF (which is true for most dynamic executables, with a value like/lib64/ld-linux-x86-64.so.2), the kernel first maps the dynamic linker into the process address space, then maps the executable's PT_LOAD segments, but does not directly run the executable's_start. - Dynamic linker (ld.so) starts execution: It is responsible for parsing
DT_NEEDED, finding actual library files, recursively loading dependencies and performing relocation, executing initialization (constructors), and finally handing control over to the executable's entry point (_start->main).
Mapping (mmap) Library Files
- The loader reads the ELF Program Headers (PT_LOAD) of each dependency
.so, mapping executable segments (text) as executable read-only, and data segments as read-write, etc.; it also handles page alignment and segment protection (mmap + mprotect). - Each library is generally mapped only once (multiple processes can share the same physical pages, provided the pages are read-only/shared).
Relocations
There are several types of relocations, falling into two important categories:
- Relocations not requiring symbol lookup (e.g., RELATIVE type): These can be adjusted directly based on the base address (for position independent code, the runtime adds the library base address to the relative offset), usually processed in batches during the startup phase for speed.
- Relocations requiring symbol lookup (e.g., R_X86_64_JUMP_SLOT / R_*_GLOB_DAT, etc.): These require searching for the corresponding definition location based on the symbol name (which may be in the executable or other libraries).
Symbol Lookup Order (Default ELF Search Rules, Roughly)
For resolving a specific symbol (e.g., function foo), the loader's search order is usually:
- The executable's global symbol table (executable overrides).
- Traverse each loaded library's dynamic symbol table in the order of the DT_NEEDED list, looking for the first matching global/weak symbol (Note: actual rules are affected by ELF version, runtime flags, RTLD_LOCAL/RTLD_GLOBAL, symbol visibility, etc.).
- If symbol versioning exists, the version tag must match.
- If loaded using
dlopenwithRTLD_GLOBAL, symbols from these libraries may participate in the resolution of subsequent libraries;RTLD_LOCALdoes not participate in other subsequent resolutions.
Important: Symbols in the executable take priority over shared libraries (this is called symbol interposition), so the executable can "override" functions in the library (this is also the basis for
LD_PRELOADto replace function implementations).
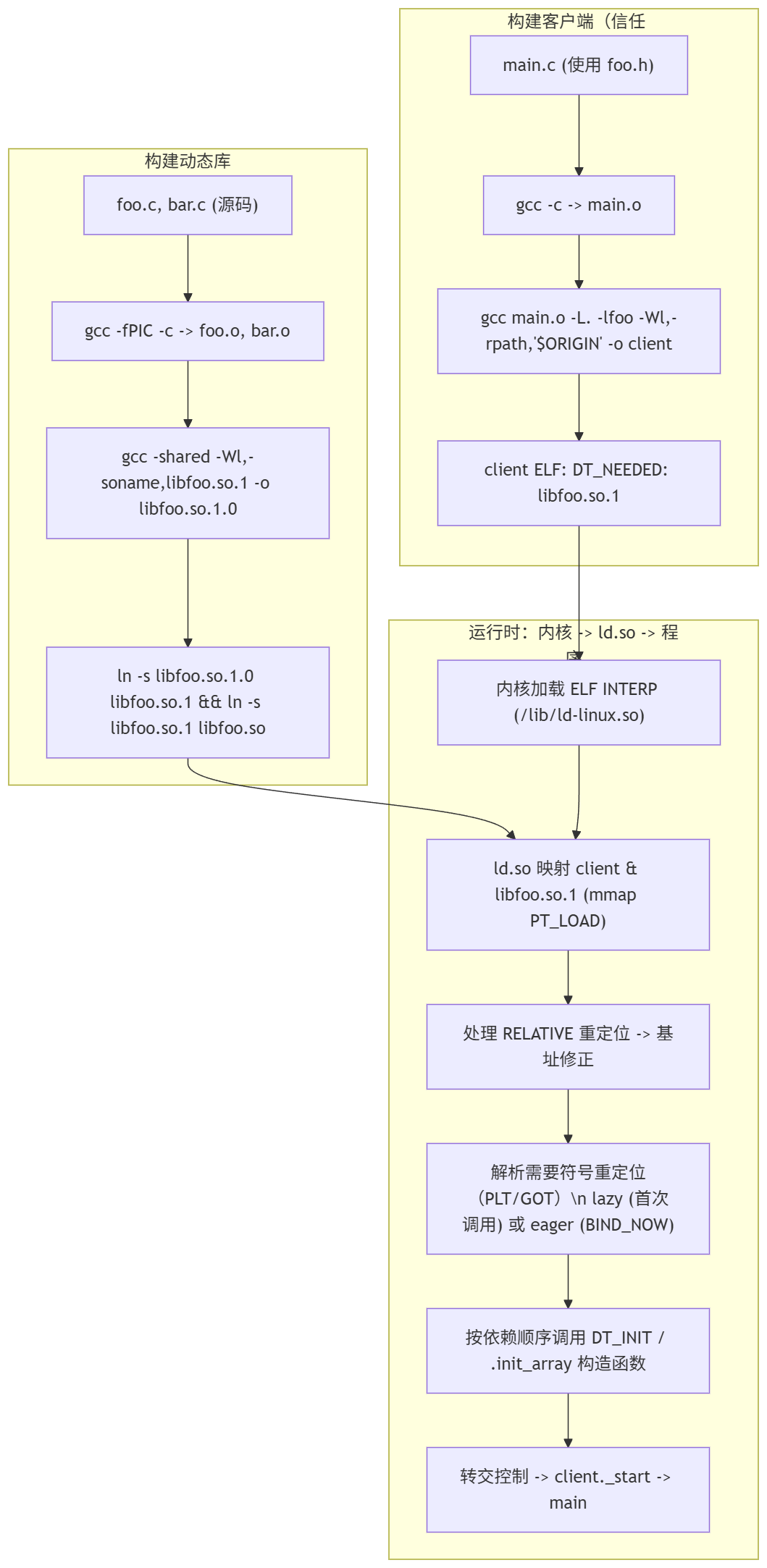
The figure above clearly explains the specific process.
Some Comparisons
I've compiled a comparison table for your reference:
| Comparison Item | Static Library | Dynamic Library (Shared / .so/.dll/.dylib) |
|---|---|---|
| Binary File Nature | .a / .lib: An archive of several .o object files; copies target code into the executable during linking. | .so / .dll / .dylib: A shared object loadable at runtime, usually Position Independent Code (PIC), with SONAME/version info. |
| Executable Integration (Link & Run) | Resolves at link time and copies needed target code into the executable (static binding); runtime does not depend on the library file. | Records DT_NEEDED (or equivalent) at link time; at runtime, the dynamic linker maps and relocates/resolves symbols in the process address space (dynamic binding, allows real-time replacement/loading). |
| Impact on Executable Size | Increases executable size (contains actual copies of library code); multiple executables will repeatedly contain the same code. | Smaller executable (only records dependencies); multiple processes share the same read-only/shared pages of the library; runtime occupies extra memory for mapping, GOT, and PLT. |
| Portability | Simple deployment: Executables are usually self-contained (easier to port under same architecture/ABI), but still affected by system/kernel/CRT. | Deployment depends on runtime environment: Requires appropriate shared library versions, loader, search paths (rpath/LD_LIBRARY_PATH/ldconfig); Cross-distro/platform compatibility is more sensitive. |
| Ease of Integration | Simple linking config (direct -l / -L or merging .o), no need to consider runtime loading; however, version upgrades require recompiling all clients. | More complex build and deployment (requires -fPIC, SONAME, rpath, symbol visibility, version scripts, etc.); but supports runtime replacement, plugins, dlopen, and allows replacing just the library file during upgrades. |
| Ease of Binary Processing/Conversion | Packing/checking/merging is intuitive (ar, nm, objdump); reversing or replacing local symbols is harder (requires re-linking). | Generating and controlling exported symbols is more complex (symbol versioning, visibility); runtime relocation & symbol resolution mechanisms are complex; but runtime dlopen/dlsym provides flexible extension capabilities. |
| Suitable for Development | Suitable for: Small tools, embedded/single-file distribution, scenarios without runtime dependencies; convenient for offline/restricted environment deployment. | Suitable for: Large projects, modular design, plugin systems, scenarios needing hot updates or reducing duplicate memory/disk usage; beneficial for team collaboration and independent library release. |
| Other Points Worth Mentioning | - Security/Bug fixes require rebuilding and redistributing all executables.- Copyright/Licenses (like GPL) may impose stricter obligations under static linking.- Usually no PLT overhead for runtime performance (calls). | - Can fix/replace library individually (quick patches).- Risks of runtime hijacking (LD_PRELOAD, RPATH injection) and latency on first call (lazy binding).- Higher requirements for platform ABI/SONAME management and deployment workflows. |
Reference
Basically derived from this book: Advanced C/C++ Compilation Technology